
アンチエイジング・ゲノム! VOL.2 ゲノム解析研究の今:全ゲノムシークエンス
- 学会誌ダイジェスト
- 2020年3月31日

中川 英刀 Hidewaki Nakagawa
理化学研究所生命医科学研究センター
ヒトゲノム配列は, 約30億個のATCG の4文字の情報が二倍体として合わさって構成されている。2003年に完成したヒトゲノム「参照」配列は,13年間で約5,000億円もの費用をかけてDNA シークエンスを行い,99%以上のヒトゲノム配列をカバーしているといわれているが,いまだ残りのギャップについて解析が進められている。約30億個のヒトゲノムの塩基配列は,多型といって個々人で配列の違いがあり,このヒトゲノム多型情報を利用し,さまざまなヒトの遺伝性疾患の家系解析が行われ,多くの疾患原因遺伝子が同定されてきた。1塩基が「参照」配列と異なる多型を一塩基多型(single nucleotide polymorphism:SNP)と呼び,個々のヒトゲノムには「参照」配列と異なるSNP が約300~400万個(全ゲノム配列の約0.1%)あるとされる。また,数キロから数十万塩基にわたり,本来2コピーあるゲノム領域が,3コピーや1コピーしかないコピー数多型(copy number variation:CNV) も10 % 存在するといわれている。
これらのゲノムの多型とヒトの病気や表現型との関連は,Genome-Wide Association Study(GWAS)という解析方法によって解明されてきている。これまで,数千個ものSNP がヒトの病気や表現型と関連することが報告されている。これら複数の多型情報を組み合わせることにより,病気のリスクを予測することができ,発症の予防や早期発見につながり,個々人の個性に適った医療(個別化医療)へと応用できる。
ヒトゲノム計画では電気泳動を自動化した機械を大量に動員して行われたが,完了後,DNA シークエンス技術は新たなフェーズに突入した。個人の全ゲノム情報を$1,000で解読できるような技術を開発するために,多くの企業がしのぎを削り(1,000ドルゲノム),いわゆる「次世代」シークエンサー(NGS)からのDNA 配列データ量は爆発的に増加し,ヒト全ゲノムシークエンス(whole genome sequencing:WGS)にかかるコストはこの10年間で急激に低下した(図1)。
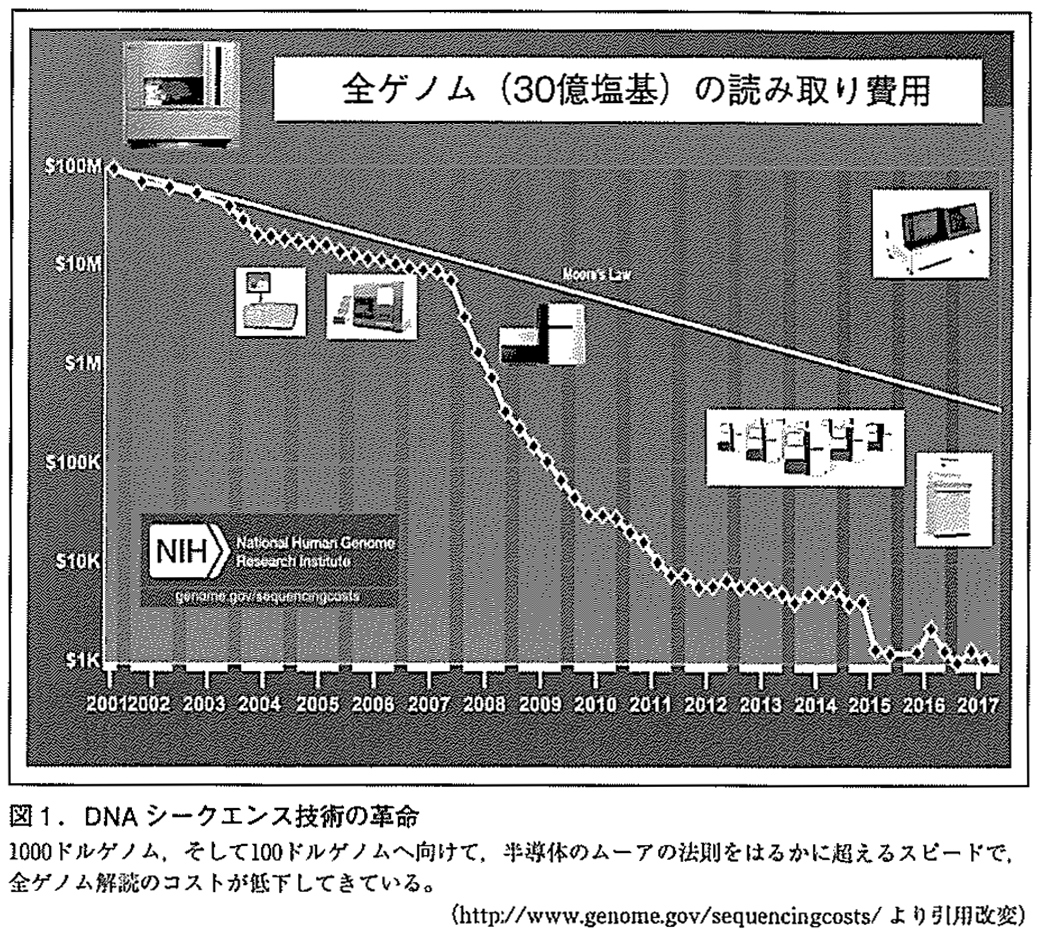
その低下速度は半導体のムーアの法則をはるかに上回る。2005年,最初の次世代シークエンサーが454社から発売され(Roche 社に買収),これを用いてDNA 二重らせん構造の発見者であるワトソン博士の全ゲノムが解読された。続けて,Solexa 社(Illumina 社に買収),SOLiD 社(Life Technology社に買収)からNGS が開発・販売され,これらは基板上で超並列に化学反応を行い,高感度CCD カメラで検出することで,数十万から数千万個のシークエンス反応が数日でできるようになった。2019年現在のNGS の最高スペックは,3,000Gb(ヒトゲノム33人相当分のデータ)を数日間で解読することができ,1,000ドルゲノムが達成されている。現在,数十万人規模でのWGS が英国(Genomic England 社)や欧米諸国で遂行されており,遺伝病の確定診断,病気のリスクなどの解釈を行ったうえで回付する医療やビジネスも展開されている。2017年の段階で,難病やがんを中心に世界で5万件以上のWGS が行われているが,2030年までには1億5千万件以上のWGS が研究および診療レベルで行われるものと予測されている。WGS が$100ほどで簡易にできるようになり,医療現場では,血液検査やX 線検査と同様に,日常的な医療検査として執り行われようになると期待されている。
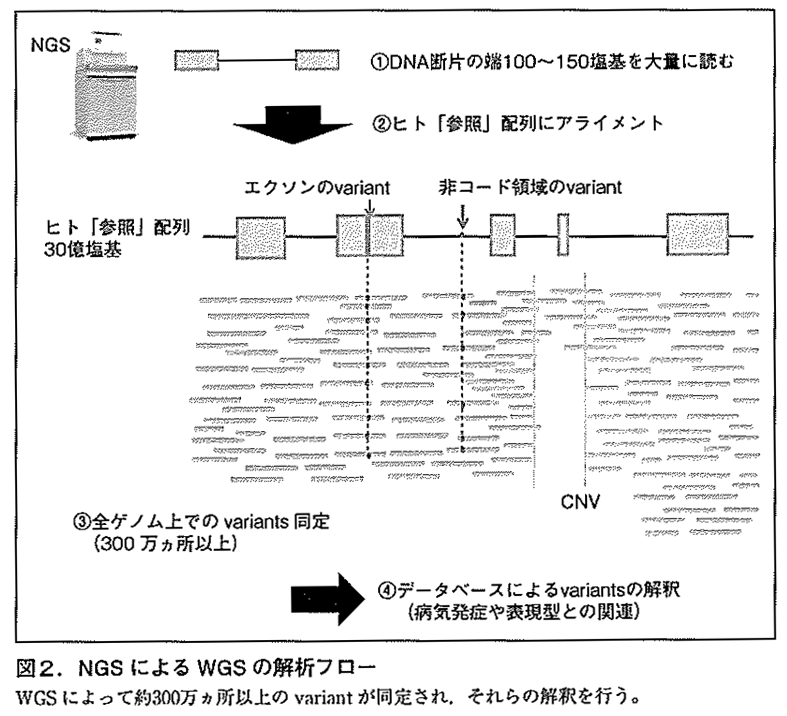
①断片化したDNA の両端100~200塩基を,NGS で大量に解読する。ヒトゲノム30億塩基=3Gb を正確に解読するには30回読む必要があり,1ゲノムに約90〜100Gb のデータが必要である。
②100~200塩基の配列情報をすべてヒト参照配列に当てはめて(アライメント),ヒトゲノムのすべて位置を平均で約30回読むかたちになる。
③ヒトゲノムのすべて位置について,参照配列と異なるvariants 部位を抽出する。 ④Call したvariants が,表現型と関連するのかデータベースを用いて探索し解釈する。
前述のGWAS 解析やvariants 解析の結果, 多くのvariants について疾患発症との関連が証明されており,欧米人のデータを中心にこれらannotation のデータはデータベース化されている。このデータベースを参照して,個々のvariants の解釈を行う。
たとえば,
①認知症のリスクvariants としてはApoE 遺伝子のε4 variant があり,このvariant をもっていると認知症のリスクが3倍になる。
②多因子疾患,生活習慣病(common diseases):GWAS 解析によって,多くのcommon variants(一般集団で1%以上の頻度で出現するvariants)が,がんや糖尿病,リウマチといった多因子疾患発症のリスクに関連することが証明されている。しかし,そのリスクは1.1~1.8倍程度であり,複数のvariants 情報を組みわせて1つの疾患の発症リスクを予測するPolygenic risk score(PRS)でのリスク診断が導入されている。しかし,このPRSの精度は人種間によって異なり,まだ医療診断としての精度は確立されていない。
③遺伝性がん,成人発症の希少難病(rare diseases):遺伝性乳がんの原因遺伝子BRCA1/2のrare variants は,主に若年性の乳がん患者や卵巣がん患者でみつかることが多いが,60歳以上のがんを発症していないヒトでも一定の頻度でみつかってきている。さまざまな難病についてリスクvariants はデータベース化がなされてきているが,みつかる多くのvariants はVUS(variants of unknown significance)であり意義不明である。日本人の一般的な乳がん患者のシークエンス解析を行うと,約4~5%の頻度でBRCA1/2のvariants がみつかるが,その8割はVUS である。
④薬剤反応性:薬の代謝や輸送に関わる遺伝子多型が,薬の副作用や効用と強く関連する(これも表現型)ことがわかってきている。抗がん剤イリノテカンの代謝に関わるUGT1A1の多型や,潰瘍性大腸炎の治療に使われるチオプリン製剤の代謝に関わるNUDT15の多型など,既存の薬の効果や副作用と強く関連しており,薬の添付文書にも記載されるようになってきている。また,免疫の型であるHLAのある特定のタイプは,薬剤アレルギーと強い関連が証明されており,そのような遺伝子型をもつヒトはその薬剤の投与は避けなければならない。
※この内容は、2019年10月発売の「アンチエイジング医学 2019年10月号(Vol.15 No.5)」に掲載されたものです。
学会誌をぜひお読みください。
http://www.m-review.co.jp/magazine/detail/J0038_1505
なお、日本抗加齢医学会会員の方には、学会誌(年6回発行)を全てお届けしております。

